
One of the hardest problems in Site Reliability Engineering is learning what to measure, and how to measure it. Sometimes one is harder than the other, and sometimes you have to learn over days, weeks, months, years, that you need to measure something – or it’ll bite you later. Of course, due to time constraints, you might not always be able to measure the reliability of a particular component. You just throw up your hands and declare in frustration “this container lives for a few minutes, press retry a few times and it’ll work eventually”.
One such measurement that I’m fed up of not having is an insight into how often Ephemeral Containers are exiting successfully (or otherwise).
Let me explain.
You are the new Site Reliability Engineer at StartupCorp. StartupCorp only has tens of Continuous Integration pipelines, but as the lone SRE, you have to try and monitor what pipelines are failing, why they are failing, and how much of an impact it has. You need to know where the pipe is leaking before the tenant complains, or the basement is flooded, or both.
The no-code way to do so would be to check every project’s pipeline page every day, looking for a dreaded “x” indicating something went wrong. After a few of them, you start to realise that the vast majority are failing tests, but some of them are failures in the CI system itself.
This is the moment you realise you only really care about a few types of failures.
- Failure of the CI agent
- Failure of a critical CI job (such as building a Docker container)
- Failure of the deployment process (network, crash, or otherwise)
- Failure to deploy
- etc.
Being a big fan of covering 90% of issues, I decided to start working on Kitsune, a system which will allow SREs to monitor three key metrics.
- Pass rate in %
- Velocity (how often the process finishes according to a baseline) in %
- Broken flows (how badly the impact affects the development flow) in %
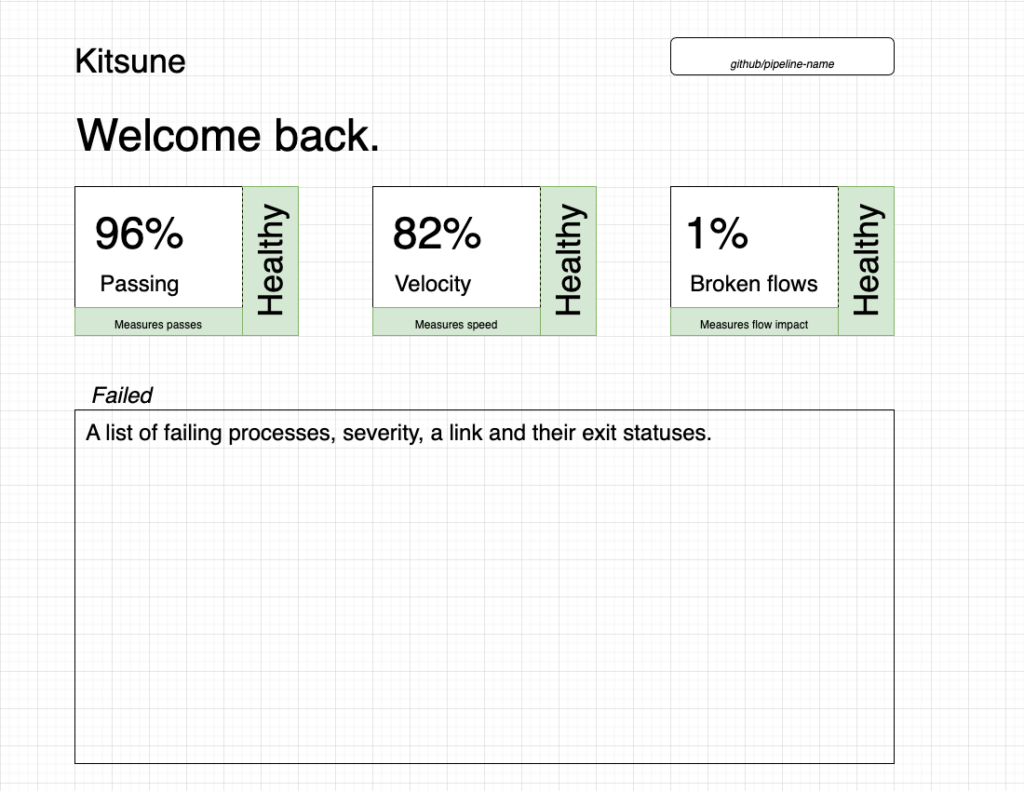
Discoverability is also a key metric, so I want failing processes to be instantly shown on this dashboard.
Initially, I would like it to be organisational-wide, but with the ability to drill down according to the “project”, “pipeline” or other differentiator. This would be defined as an environment variable which a wrapper bash script sending these metrics would take in.
Of course, alerting would come shortly after an initial release.
Hopefully this will help Site Reliability Engineers reign in ephemeral containers at scale, helping to focus on the KPIs for systems like these – and reach 100% reliability!
If you’re interested in this project, please add me on LinkedIN, and keep an eye on this space for more updates.